ReferIt3D: Neural Listeners for Fine-Grained
3D Object Identification in Real-World
Scenes
ECCV 2020, Oral
- Panos Achlioptas Stanford University
- Ahmed Abdelreheem KAUST
- Fei Xia Stanford University
- Mohamed Elhoseiny Stanford University, KAUST
- Leonidas Guibas Stanford University
Abstract
In this work we introduce the problem of using referential language to identify common objects in real-world 3D scenes. We focus on a challenging setup where the referred object belongs to a fine-grained object class and the underlying scene contains multiple object instances of that class. Due to the scarcity and unsuitability of existent 3D-oriented linguistic resources for this task, we first develop two large-scale and complementary visio-linguistic datasets: i) Sr3D, which contains 83.5K template-based utterances leveraging spatial relations among fine-grained object classes to localize a referred object in a scene, and ii) Nr3D which contains 41.5K natural, free-form, utterances collected by deploying a 2-player object reference game in 3D scenes. Using utterances of either datasets, human listeners can recognize the referred object with high (>86%, 92% resp.) accuracy. By tapping on the introduced data, we develop novel neural listeners that can comprehend object-centric natural language and identify the referred object directly in a 3D scene. A key technical contribution is designing an approach for combining linguistic and geometric information (in the form of 3D point clouds) and creating multi-modal (3D) neural listeners. Importantly, we show that architectures which promote object-to-object communication via graph neural networks outperform context-unaware alternatives, and that fine-grained object classification is a significant bottleneck for language-assisted 3D object identification.
Video
Overview & Intuitions
I. You contrast explicitly objects of the same fine-grained object class only. Why?

Because this enables the human (or neural) speakers to use minimal details to disambiguate the “target” object, fostering the production of efficient & fine-grained references. Put it simple, if you contrast an armchair to a target office-chair, you can trivially utter: “the office chair”. Furthemore, the inclusion of explicit bounding boxes that surround the contrasting objects helps our annotators focus on the task, especially since the ScanNet 3D reconstructions are far from noise-free.
II. You contrast objects for which at least one same-fine-grained distractor exists in the scene. Why?
Because similarly to the above, this forces the reference to go beyond fine-grained or simple-object classification! I.e., if the target is the only refrigerator of the scene, the reference: “the refrigerator” is good enough, no?
III. You collected a large dataset, Nr3D which natural language. Why bother making also a synthetic one focusing on spatial-relations?

Because as we verified in Nr3D, spatial-reasoning ("left of," "between," etc.) is ubiquitous in natural reference. Sr3D focuses on that aspect only — disentangling the reference problem nicely from other object properties such as their color or shape. Also, even (naively) adding Sr3D to Nr3D in the training data improves the listeners' performance in comprehending natural language!
IV. Are all contrasting-contexts and produced language qualitatively about the same? Or, there are important intrinsic differences among them?

No, they are not the same. For instance, you might contrast a lamp with a single lamp or with four of them (compare “easy” vs. “hard” in above Figure). Or, you can use in your language enough elements that allow another person (or a robot) to find the target item among all (!) objects of the scene, making the reference—object pair “Scene-Discoverable” (in Fig. see references that have a “tick” under SD). Last, it is different from uttering an object-reference having a specific view in mind, e.g., “The lamp on the right, in between the beds,” which implies that the listener needs to find the front-face of the bed Vs. Making a reference like “The lamp closer to the white armchair,” which in theory only requires one to pinpoint the armchair without caring about its front-back views. I.e., it is view-independent (VI).
Dataset
Browsers
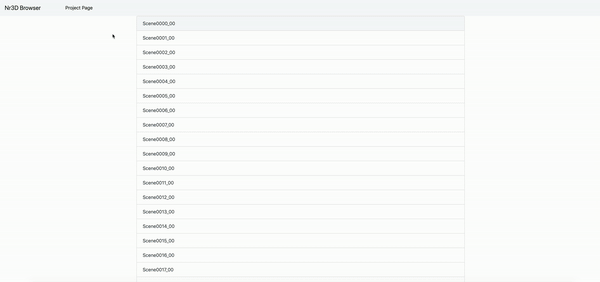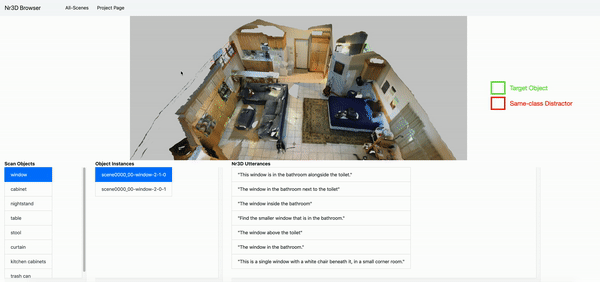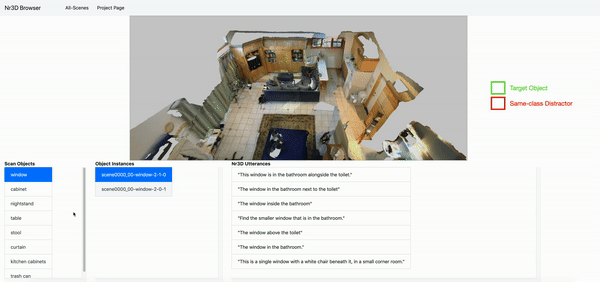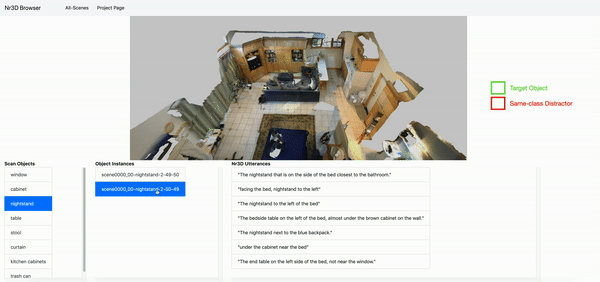
- You can explore the Nr3D and Sr3D utterances inside the 3D ScanNet Scenes here: Nr3D browser, Sr3D browser.
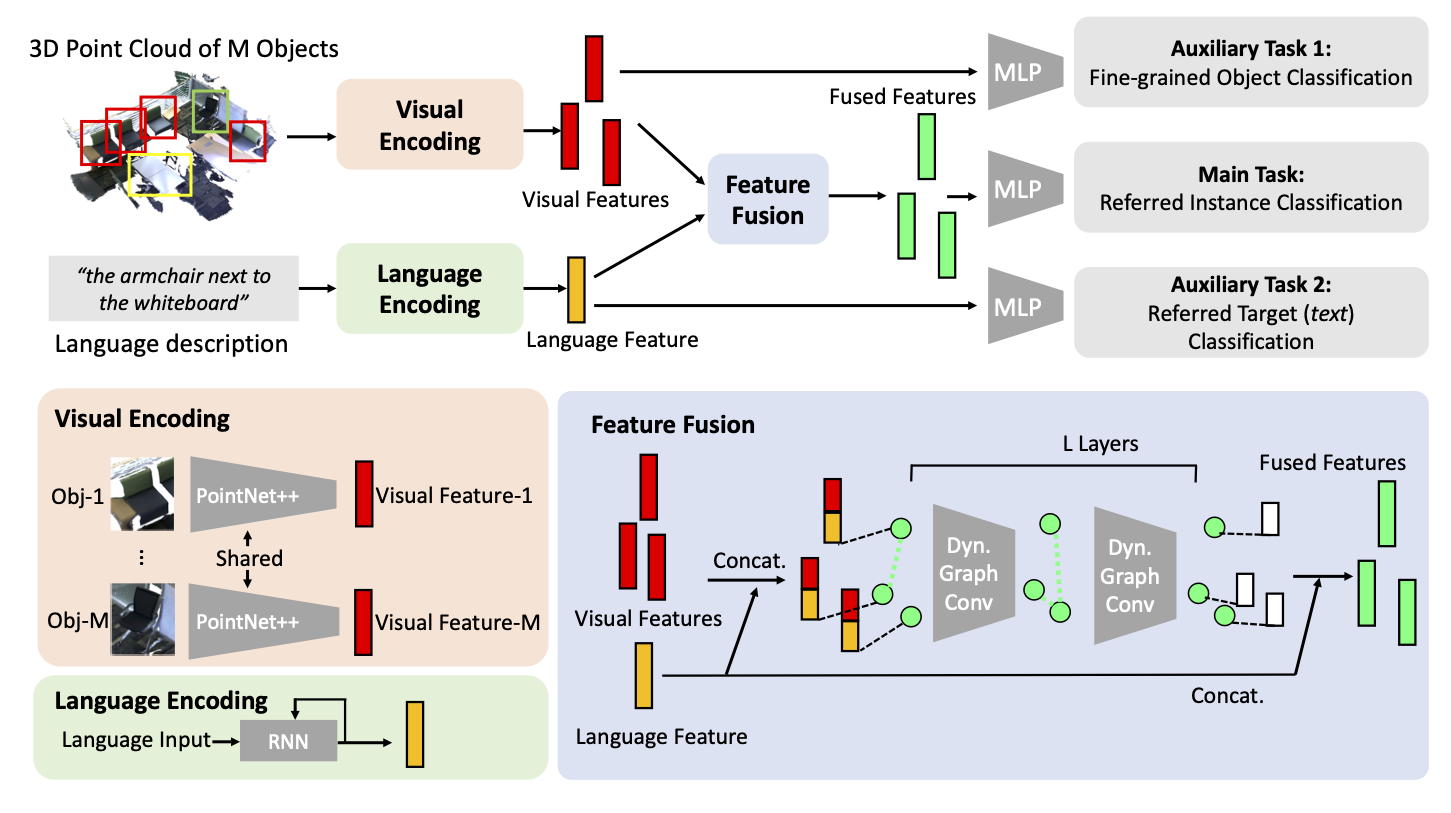
Method: ReferIt3DNet
Qualitative Results

Citation
If you find our work useful in your research, please consider citing:
@inproceedings{achlioptas2020referit_3d,
title={{ReferIt3D}: Neural Listeners for Fine-Grained 3D Object Identification in Real-World Scenes},
author={Achlioptas, Panos and Abdelreheem, Ahmed and Xia, Fei and Elhoseiny, Mohamed and Guibas, Leonidas J.},
booktitle={16th European Conference on Computer Vision (ECCV)},
year={2020}
}
ReferIt3D Benchmark Challenges
We wish to aggregate and highlight results from different approaches tackling the problem of fine-grained 3D object identification via language. If you use either of our datasets with a new method, please let us know! so we can add your method and attained results in our benchmark-aggregating page.
Acknowledgements
The authors wish to acknowledge the support of a Vannevar Bush Faculty Fellowship, a grant from the Samsung GRO program, and the Stanford SAIL Toyota Research Center, NSF grant IIS-1763268, KAUST grant BAS/1/1685-01-01, and a research gift from Amazon Web Services. They also want to thank Iro Armeni, Angel X. Chang, and Jiayun Wang for inspiring discussions and their help in bringing this project to fruition. Last but not least, they want to express their gratitude to the wonderful Turkers of Amazon Mechanical Turk, whose help in curating the introduced datasets was paramount.